Performance testing of Ansible-deploy driver for OpenStack Ironic
Posted on Fri 01 September 2017 in work
What and why are we testing
For more than a year me and my colleagues are developing and promoting a new deploy driver interface for OpenStack ironic service. Contrary to the standard direct or iscsi deploy interfaces that depend on ironic-python-agent service (IPA) running in the deploy ramdisk, this new ansible deploy interface is using Ansible to provision the node, with the steps to execute during provisioning or cleaning defined as Ansible playbooks/roles/tasks etc. The main advantage of this approach is greater flexibility regarding fine-tuning of the provisioning process this deploy interface allows.
This ansible deploy interface and classic ironic drivers using it are already available as part of ironic-staging-driver project [1], and we are in the process of proposing [2] to include this interface to the ironic project itself.
One of the topics raised during discussions is the performance of this new driver interface. Contrary to the direct deploy interface that offloads most of the work to be executed by IPA that runs on the node being provisioned, this new interface involves executing code on the side of ironic-conductor service, thus we were asked to show that the ansible deploy interface can cope with deploying several nodes in parallel (50 at least) without severe performance degradation on the side of ironic-conductor service/host.
Testbed
Lab setup and tests were performed by my colleague Vasyl Saienko [3], with me mostly consulting on setting up and tuning the ansible deploy interface and Ansible itself.
The lab consisted of 4 baremetal nodes with the following relevant stats:
- 1x ironic host
- CPU: Intel(R) Xeon(R) CPU E5-2620, 32 cores, RAM: 32GB
- 3x enrolled into ironic
- CPU: Intel(R) Xeon(R) CPU E5-2650, 32 cores RAM: 64GB
We have deployed a minimal single host ironic installation as of 7.0.2 version (Ocata release) on the ironic host node using Mirantis Cloud Platform 1.1 [4]. The Ansible-deploy interface was taken from ironic-staging-drivers project as of stable/ocata branch. The deployment also included OpenStack Identity (keystone) and Networking (neutron) services, also of Ocata release.
We used Ansible 2.3.2.0 pip-installed from PyPI.
We enrolled the 3 slave baremetal nodes in ironic, deployed them with Ubuntu Xenial image, created 100 VMs on each of them, and enrolled those to ironic using virtualbmc utility to simulate IPMI-capable hardware nodes. This effectively gave us 300 ironic nodes to test deployment on.
Overall order of the tests was the following:
- pxe_ipmitool_ansible driver, deploy 50 nodes, repeat 3 times
- agent_ipmitool driver, deploy 50 nodes, repeat 3 times
- agent_ipmitool driver, deploy 100 nodes, repeat 3 times
- pxe_ipmitool_ansible driver, deploy 100 nodes, repeat 3 times
The deploy ramdisk used for both drivers was the tinyipa image as of stable/ocata rebuilt for usage with ansible deploy interface. We provisioned nodes with standard Ubuntu Xenial cloud image.
Concurrent deployment was done via trivial bash script calling ironic client commands in a for loop. For each iteration "virtual" nodes to be provisioned were chosen to be equally distributed between real baremetal nodes to decrease possible congestion.
Monitoring was performed with Cacti, with results presented and discussed below.
Lab tuning
- The static image store was moved outside of ironic node
- due to physical network layout of the lab, this separate storage had better connection speed with baremetal nodes, and thus was performing better
- The timeout for downloading the image [5] was increased.
- Current hard-coded value is more suitable for small cirros image used in OpenStack CI, and turned out to be not sufficient for downloading the image we were using given performance of our image store
- We plan to make such values actually configurable later
- We switched Ansible to use paramiko transport instead of the default
smart [6]
- We experienced weird problems with SSH timeouts both on initial connection and when executing tasks.
- There are number of bugs reported against Ansible that might be relevant, e.g. [7].
- Using paramiko for SSH may have introduced an extra performance cost compared to the native SSH binaries.
- We increased the internal_poll_interval Ansible configuration setting
[8] to 0.01 (from default 0.001).
- Available since Ansible 2.2, this setting was specifically introduced for better CPU-wise performance of Ansible in use-cases that do not require responsiveness of ansible-playbook process console output.
Results and discussion
Nodes per driver
This plot shows the number of nodes registered per each driver to set time frame reference for further graphs.
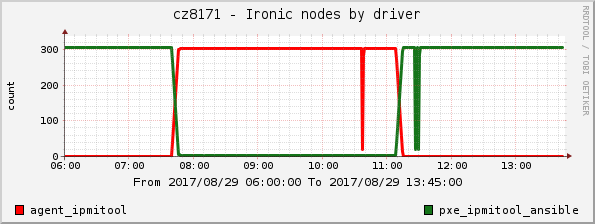
And we immediately see one of the troubles we stumbled upon - the dips in the second graph around 10:35 and 11:30. These graphs were plotted by Cacti periodically polling the ironic API for number of nodes - and at these points requests simply timed out. It happened for both drivers, so we tend to attribute this to the fact that ironic API was running as the eventlet sever instead of WSGI behind a more robust webserver (Note that running ironic as WSGI app was not yet officially supported in Ocata release).
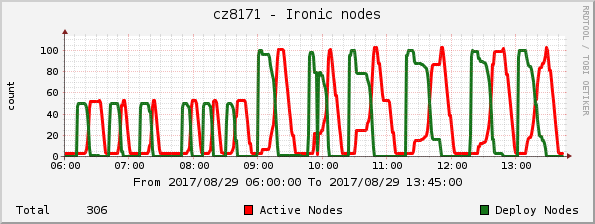
Nodes by state
This plot shows the number of nodes in either "deploying/wait-callback" or "active" state.
Ironic host performance stats
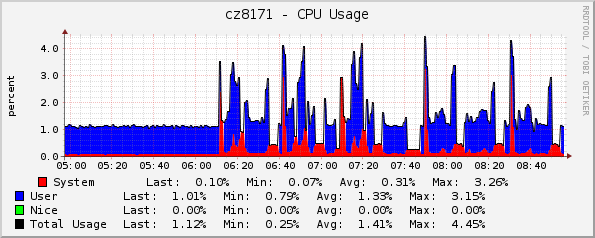
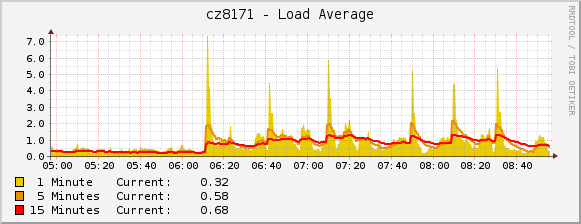
Batches of 50
- CPU usage
- Load average
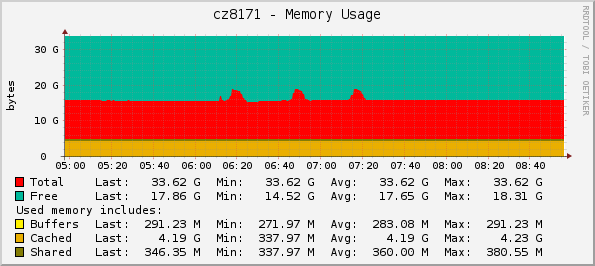
- Memory usage
- TCP counters
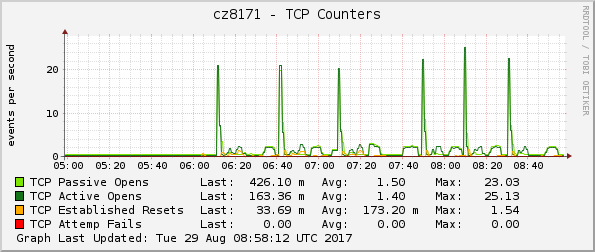
The sharp spikes in CPU utilization are well attributed to the TFTP server serving multiple concurrent requests.
We also see that using ansible deploy interface consumes more CPU (about 3% at peaks) and more RAM (about 3 GB) than agent-deploy. This is due to the task execution engine (Ansible) is being run locally on conductor instead of remotely on the node being deployed (IPA).
Nevertheless the overall time to provision all nodes and the average CPU load is nearly the same, and the toll multiple Ansible processes take on the conductor node is well within of what a real server suitable for such scaled baremetal cloud can handle.
Overall test (both 50 and 100 batches)
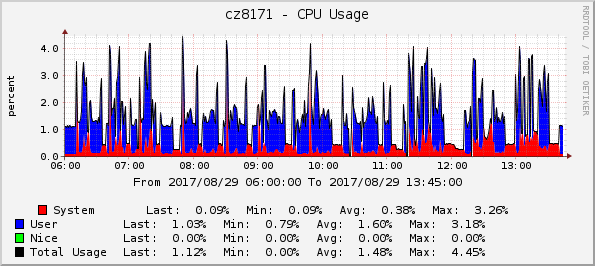
- CPU usage
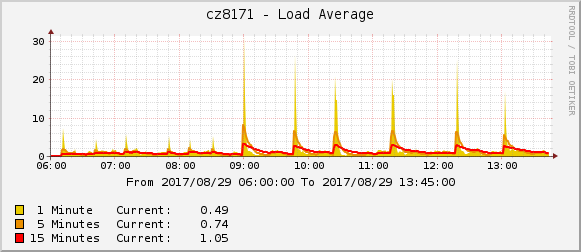
- Load average
- Memory usage
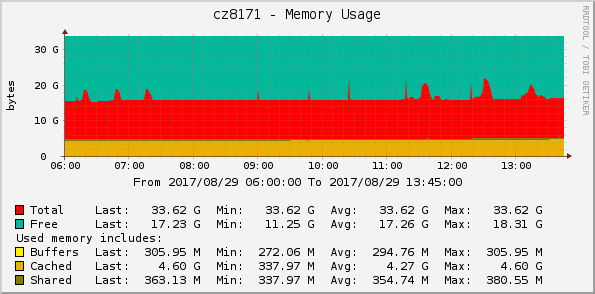
- TCP counters
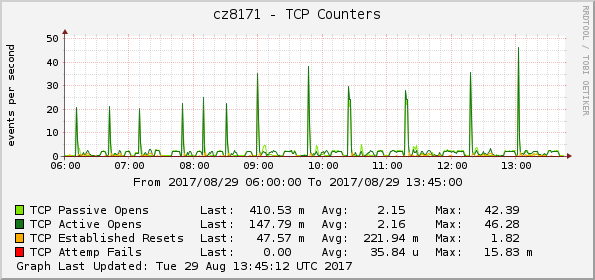
As expected, using direct driver interface scales better whith increasing the number of nodes and is close to O(1), while overhead of using ansible deploy interface scales closer to O(n) of number of nodes, especially for RAM consumption.
We tend to attribute such scaling difference to the fact that current internal architecture of ironic does not allow us to use Ansible as it was designed, with one ansible-playbook process executing the same playbook with identical input variables against several nodes. Instead, we launch separate ansible-playbook process for each node even when nodes are being provisioning with the same image and other settings, which obviously has negative impact on resources used.
This difference has to be taken into account when planning an (under)cloud ironic deployment that is going to allow usage the ansible deploy interface.
Conclusion
Overall we think that the ansible deploy interface performs and scales within acceptable limits on a quite standard server hardware.
References
| [1] | http://git.openstack.org/cgit/openstack/ironic-staging-drivers/tree/ironic_staging_drivers/ansible |
| [2] | https://review.openstack.org/#/c/241946/ |
| [3] | https://launchpad.net/~vsaienko |
| [4] | https://www.mirantis.com/software/mcp/ |
| [5] | http://git.openstack.org/cgit/openstack/ironic-staging-drivers/tree/ironic_staging_drivers/ansible/playbooks/roles/deploy/tasks/download.yaml?h=stable/ocata#n10 |
| [6] | http://docs.ansible.com/ansible/latest/intro_configuration.html#transport |
| [7] | https://github.com/ansible/ansible/issues/24035 |
| [8] | http://docs.ansible.com/ansible/latest/intro_configuration.html#internal-poll-interval |